发布于:2022/6/2 10:11:10 | 11362 次阅读

英特尔重申,随着未来几年转向更新的制造工艺和封装技术,它正在整合其高性能CPU和GPU的路线图。 据介绍,该公司正在将CPU和GPU阵容合并成一个芯片(代号为FalconShores),英特尔将其称为XPU。英特尔超级计算事业部副总裁兼总经理JeffMcVeigh在ISCHigh之前的新闻发布会上表示,FalconShores是一项“更大的架构”变化,它将x86和Xe图形核心整合到一个封装中。
 holle
|
发布于:2022-06-02
0评论
0赞
holle
|
发布于:2022-06-02
0评论
0赞

有关苹果增强现实(AR)头显的消息是当前电子信息与消费领域,人们zui为关注的行业热点之一。此前曾有消息称,其将于2022年底发布。海通国际证券在近日发布一份报告中预计,该设备或被推迟到2023年di一季度。尽管再被推迟,苹果AR头显的关注度依然不减。业界普遍期待,凭借苹果强大的定制化自研芯片能力,这款产品或将为AR设备市场打开一条上升通道。而这一情况亦从另一侧面显示出,定制化芯片对于AR设备发展
holle
|
发布于:2022-04-29
0评论
0赞
瑞萨电子推出用于RZ/G2L、RZ/V2L的完整电源解决方案
新产品可提升系统可靠性,降低整体成本,支持四层PCB板 2021年8月6日,日本东京讯-全球半导体解决方案供应商瑞萨电子集团(TSE:6723)今日宣布,推出RAA215300PMIC(电源管理IC),该产品是针对人工智能(AI)应用RZ/G2L、RZ/V2L微处理器(MPU)的完整电源解决方案,主要功能包括九个电源输出通道、一个内置充电器和一个实时时钟;其高集成度可降低设计复杂
Electronic135
|
发布于:2021-08-06
0评论
0赞

艾迈斯欧司朗通过光谱传感器为COVID-19提供分子检测解决方案
·新型BiologyWorksk(now)?设备提供高准确的COVID-19检测或其他分子测定,重新定义了医疗保健的检测标准; ·艾迈斯欧司朗的多光谱传感器能够通过分析鼻拭子样本实现病毒分子检测; ·灵活的光谱传感器针对所有光波长进行标准化,使BiologyWorks?能够使用不同的测定法来识别COVID-19、甲型/乙型流感、血糖水平和STD等信息。
Electronic135
|
发布于:2021-07-09
0评论
0赞

科锐GaN-on-SiC功率放大器结合MaxLinear线性化技术,高效赋能新型超宽带5G
新型GaN-on-SiC线性化解决方案赋能5G基站,支持更多移动通信用户并提供高速数据传输 2021年7月5日,美国北卡罗莱纳州达勒姆讯––全球碳化硅技术领先企业科锐Cree,Inc.(美国纳斯达克上市代码:CREE)于近日宣布了与MaxLinear,Inc.(美国纽约证券交易所上市代码:MXL)的成功合作。MaxLinear是射频(RF)、模拟、数字和混合信号集成电路的领先供应
Electronic135
|
发布于:2021-07-06
0评论
0赞
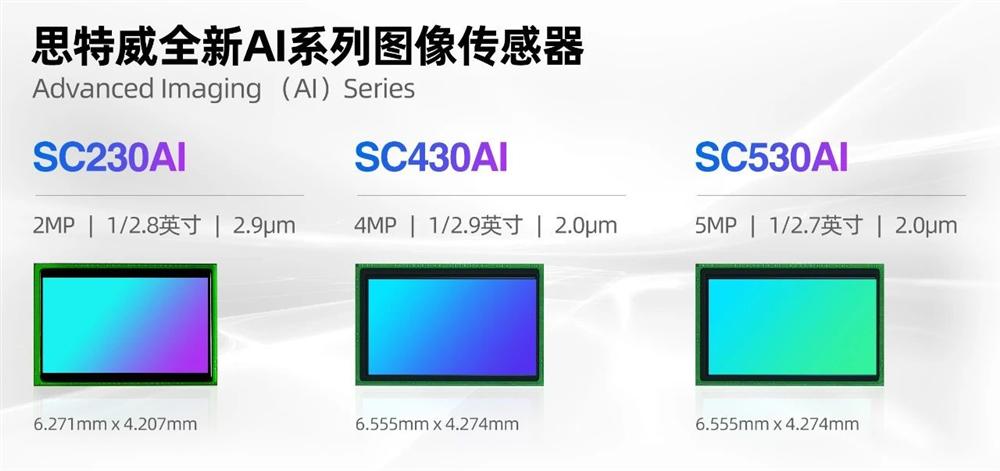
2021年6月22日,中国上海—技术先进的CMOS图像传感器供应商思特威科技(SmartSensTechnology)今日宣布,正式推出基于其全性能升级技术SmartClarity?-2的三款图像传感器新品——SC230AI/SC430AI/SC530AI。 伴随5G与AI智能化的发展,安防监控行业已逐渐进入全新的智能安防时代,而其中CMOS图像传感器对成像质量起着关键性作用
Electronic135
|
发布于:2021-06-22
0评论
0赞
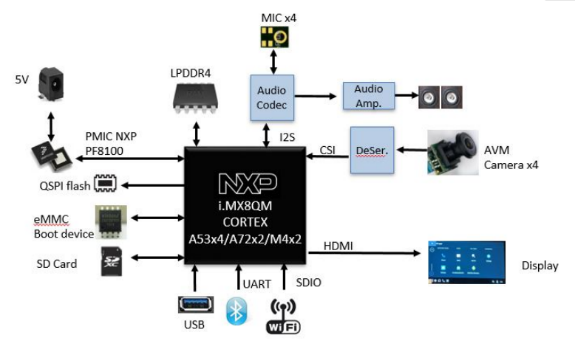
大联大品佳集团推出基于NXP i.MX8QM的AI影像辨识与车辆识别方案
2021年5月13日,致力于亚太地区市场的领先半导体元器件分销商---大联大控股宣布,其旗下品佳推出基于恩智浦(NXP)i.MX8QM的AI影像辨识与车辆识别方案。 当今社会正逐渐发展成为一个以多媒体为中心,并且高度依赖数据和自动化的经济体系。而汽车产业作为体系中重要的一环,在众多科技的推进下,也正经历着前所未有的智能化升级。随着自动驾驶和辅助驾驶技术愈发成熟,如何
Electronic135
|
发布于:2021-05-14
0评论
0赞

Melexis 推出面向消费类应用的紧凑型低压 3D 磁力计
MLX90392将荣获专利的Triaxis?霍尔磁感应技术 应用到注重节省成本的白色家电、智能仪表、游戏和住宅安保等领域 2021年5月7日,比利时泰森德洛-全球微电子工程公司Melexis宣布推出面向白色家电、消费类电子产品和智能仪表应用的三轴磁场传感器芯片MLX90392,可与其他组件(如逻辑器件)共享1.8V的电源轨工作。 MLX903
Electronic135
|
发布于:2021-05-11
0评论
0赞


//评论区